Sổ tay LLM
Sổ tay kiến thức giúp người mới hiểu nền tảng về NLP, LLM và kiến trúc Transformer, từ cách mô hình xử lý ngôn ngữ, giải các bài toán khác nhau, đến cách suy luận khi tạo ra văn bản. Bài viết cũng nhấn mạnh giới hạn quan trọng như bias, hallucination và các lưu ý khi dùng mô hình thực tế.

I. Tổng quan
NLP (Natural Language Processing): Là lĩnh vực nền tảng rộng lớn. Nhiệm vụ của nó là giúp máy tính hiểu, diễn dịch và tạo ra ngôn ngữ con người (ví dụ: dịch máy, phân tích cảm xúc câu nói).
LLM (Large Language Models): Là thế hệ tiến tiến nhất và là một tập hợp con cực mạnh của NLP. Chúng khổng lồ về kích thước, được huấn luyện trên lượng dữ liệu khủng. Điểm kỳ diệu của LLM (như GPT, Claude) là chúng có thể làm được vô số tác vụ ngôn ngữ khác nhau mà gần như không cần phải huấn luyện lại từ đầu cho từng tác vụ riêng biệt. Việc hiểu NLP truyền thống là bệ phóng bắt buộc để làm chủ LLM.
Hiểu đơn giản: NLP là lĩnh vực, LLM là mô hình trong lĩnh vực đó.
II. NLP
NLP không đơn thuần là dạy máy tính nhận diện từng từ rời rạc. Mục tiêu tối thượng của nó là giúp máy tính hiểu được ngữ cảnh (context).
- Phân loại cả câu: Đánh giá xem một bình luận là tích cực hay tiêu cực (Sentiment analysis), phát hiện email rác (Spam), kiểm tra ngữ pháp hoặc tính logic giữa hai câu.
- Phân loại từng từ: Xác định danh từ, động từ hoặc Nhận dạng thực thể (Named Entity - tìm ra đâu là Tên người, Địa điểm, Tổ chức trong câu).
- Tạo văn bản: Tự động điền tiếp đoạn văn hoặc điền vào chỗ trống (Masked words).
- Trích xuất thông tin: Đưa ra một đoạn văn và một câu hỏi, yêu cầu AI tìm đúng câu trả lời nằm trong đoạn văn đó.
- Chuyển đổi câu: Dịch thuật (Translation) hoặc Tóm tắt văn bản (Summarization).
Lưu ý thêm: NLP hiện nay còn vươn ra ngoài văn bản chữ viết, xử lý cả giọng nói (Speech-to-text) và hình ảnh (Tạo mô tả cho bức ảnh).
III. LLM
LLM (như GPT, Claude) là một thế hệ đột phá của NLP. Chúng được đào tạo trên một lượng dữ liệu văn bản khổng lồ. Sự khác biệt tạo nên năng lực đặc biệt của LLM bao gồm 4 yếu tố:
- Scale (Quy mô siêu khủng): Chứa từ hàng triệu đến hàng trăm tỷ tham số.
- General capabilities (Đa nhiệm không cần đào tạo lại): Trước đây, muốn phân loại rác thì cần 1 mô hình AI riêng, muốn dịch thuật cần 1 mô hình khác. Giờ đây, một LLM duy nhất có thể làm tất cả.
- In-context learning (Học theo ngữ cảnh): Bạn chỉ cần đưa ra vài ví dụ ngay trong câu prompt, LLM sẽ tự học và làm theo mẫu ngay lập tức.
- Emergent abilities (Năng lực tự phát): Khi kích thước mô hình đạt đến một ngưỡng khổng lồ nhất định, chúng tự nhiên phát triển các kỹ năng mới mà những kỹ sư tạo ra chúng không hề lập trình sẵn (ví dụ: tự biết làm toán, tự biết viết code).
IV. Các vấn đề về Bias và Limitations của LLM
Pretrained model học từ dữ liệu rất lớn trên Internet nên có thể hấp thụ cả thiên lệch có sẵn trong dữ liệu.
Khi chúng ta đọc "Tôi đói" và "Tôi buồn", ta dễ dàng phân biệt. Nhưng với máy tính, chúng chỉ hiểu con số. Làm sao để biến chữ thành số mà vẫn giữ được ý nghĩa là một thách thức lớn. Thêm vào đó, ngôn ngữ loài người chứa đựng sự mơ hồ, văn hóa, sự châm biếm và hài hước. LLM bù đắp điều này bằng cách đọc thật nhiều, nhưng ở những tình huống phức tạp, chúng vẫn chưa thể sánh bằng sự thấu cảm của con người.
Hallucinations (Ảo giác): Tạo ra thông tin sai lệch hoàn toàn nhưng lại trình bày với thái độ cực kỳ tự tin và logic. Nếu bạn đang viết một cuốn tiểu thuyết viễn tưởng hoặc cần ý tưởng marketing điên rồ, việc AI tạo ra những liên kết không có thật (ảo giác) lại là một tính năng vô giá, chứ không phải là lỗi (bug).
Không thực sự hiểu: LLM không có nhận thức về thế giới thực. Dưới lớp vỏ ngôn ngữ, chúng chỉ đang tính toán xác suất từ (token) nào nên xuất hiện tiếp theo dựa trên các mô hình thống kê.
Nếu dữ liệu huấn luyện có chứa sự phân biệt chủng tộc, giới tính, mô hình sẽ học và lặp lại chính xác những định kiến đó.
Context windows (Giới hạn bộ nhớ ngắn hạn): Mô hình chỉ có thể nhớ và xử lý một đoạn văn bản có độ dài nhất định trong một lần hội thoại (mặc dù công nghệ này đang được cải thiện rất nhanh).
Ngốn tài nguyên: Cần những siêu máy tính và lượng điện năng khổng lồ để vận hành.
Và hãy nhớ rằng, Fine-tuning chỉ dạy cho mô hình cách trả lời đúng định dạng của bạn, nhưng nó không xóa bỏ được những định kiến đã ăn sâu vào hàng tỷ tham số trong quá trình Pretraining.
V. Inference với LLMs
Quá trình Inference (Suy luận) là lúc bạn đưa mô hình vào sử dụng thực tế (đặt câu hỏi và chờ nó trả lời), khác hoàn toàn với quá trình Training (Huấn luyện)
LLM tạo văn bản theo kiểu từng token một. Mỗi bước nó dự đoán token kế tiếp, nối vào chuỗi, rồi tiếp tục lặp lại.
Cơ chế đoán từ
Các LLM (như GPT) tạo ra văn bản theo nguyên tắc đoán từng-từ-một. Để viết ra từ thứ 100, nó phải đọc lại toàn bộ 99 từ trước đó. Vòng lặp này lặp đi lặp lại khiến quá trình Inference cực kỳ tốn tài nguyên và dễ bị nghẽn cổ chai (bottleneck) về bộ nhớ.
Để không phải tính toán lại từ đầu mỗi khi sinh ra một từ mới, các kỹ sư tạo ra cơ chế KV Cache (Key-Value Cache). Mô hình sẽ nhớ lại các trạng thái tính toán của các từ cũ và lưu vào RAM của GPU. Nhờ vậy, tốc độ trả lời tăng lên đột phá, nhưng đánh đổi lại là nó ngốn VRAM (RAM của card đồ họa) cực kỳ khủng khiếp nếu đoạn chat quá dài.
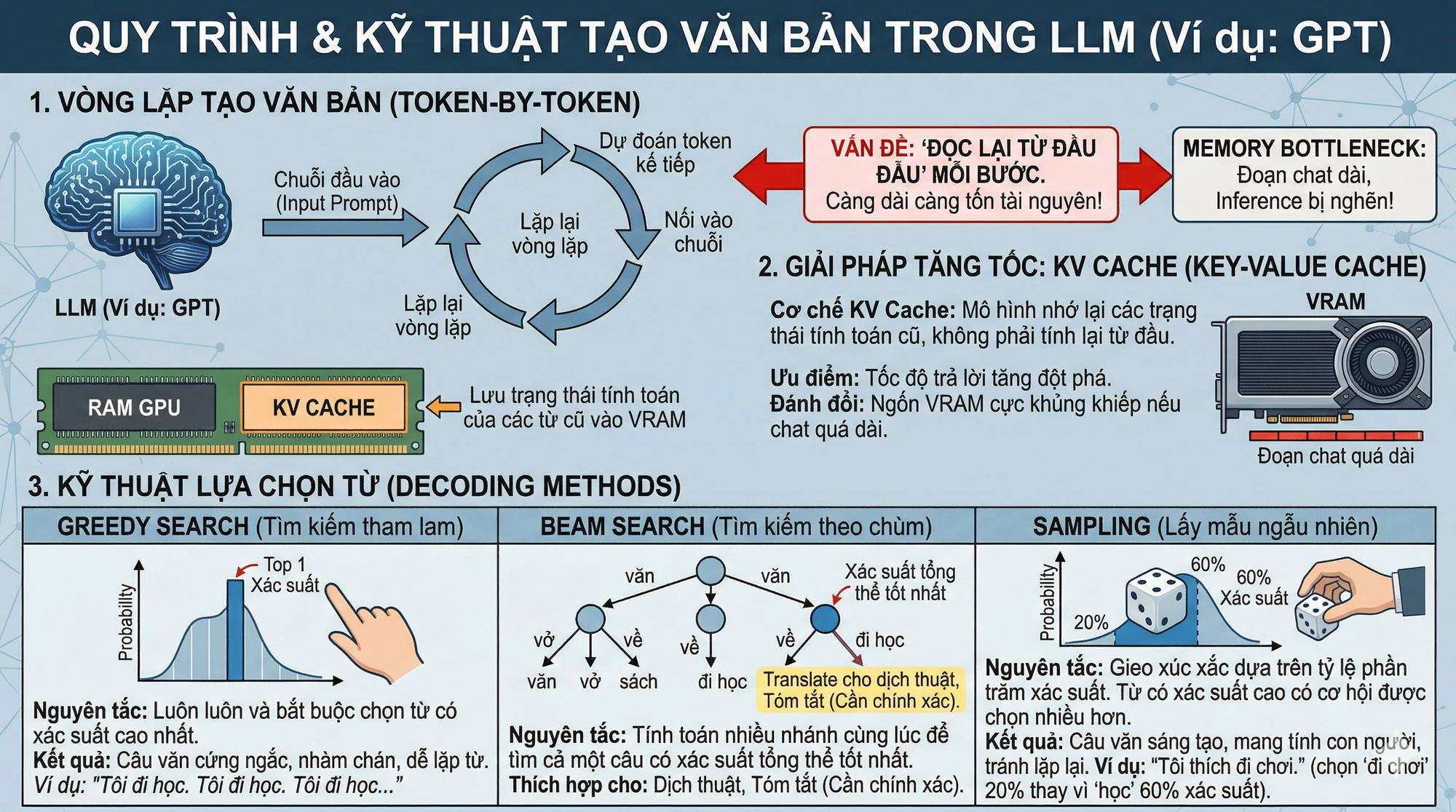
Khi AI đoán từ tiếp theo, thực chất nó đang tính ra một bảng xác suất cho hàng chục ngàn từ vựng. Làm sao nó chọn được từ nào để viết ra?
- Greedy Search (Tìm kiếm tham lam): AI luôn luôn và bắt buộc chọn từ có xác suất cao nhất (Top 1). Nhược điểm: Câu văn trở nên cứng ngắc, nhàm chán và dễ bị lặp từ.
- Beam Search (Tìm kiếm theo chùm): Thay vì chỉ nhìn 1 bước, AI sẽ tính toán nhiều nhánh cùng lúc (ví dụ 5 nhánh) để tìm ra cả một câu có xác suất tổng thể tốt nhất. Thích hợp cho Dịch thuật hoặc Tóm tắt.
- Sampling (Lấy mẫu ngẫu nhiên): AI sẽ gieo xúc xắc dựa trên tỷ lệ phần trăm. Từ có xác suất 70% sẽ có 70% cơ hội được chọn. Cách này giúp câu văn sáng tạo và mang tính con người hơn.
Các nút vặn ma thuật: Temperature, Top-K, Top-p
Khi dùng Sampling, nếu không kiểm soát, AI có thể chọn những từ vô nghĩa. Bạn cần dùng các nút vặn này trong code:
Temperature (Nhiệt độ):
- Mức thấp (ví dụ 0.1-0.3): AI cẩn trọng, logic, trả lời y hệt nhau mỗi lần hỏi (Tốt cho toán học, lập trình).
- Mức cao (ví dụ 0.9-1): AI phá cách, bay bổng, sáng tạo (Tốt cho viết văn, làm thơ).
Top-K: Ép AI chỉ được phép quay xổ số trong K từ có khả năng cao nhất (ví dụ Top 50). Loại bỏ hoàn toàn những từ ngớ ngẩn.
Top-p (Nucleus Sampling): Tinh vi hơn Top-K. Nó cộng dồn xác suất các từ từ cao xuống thấp cho đến khi đạt một ngưỡng p (ví dụ 90%). Bất kể là 5 từ hay 50 từ, miễn tổng xác suất đạt 90% thì AI sẽ chọn ngẫu nhiên trong nhóm đó.
Khi bạn gọi API của OpenAI hay Claude, hãy thiết lập tham số theo đúng công thức sau tùy vào bài toán của bạn (có thể tinh chỉnh để thử).
Công thức cho Chatbot tư vấn, Lập trình viên, Trích xuất dữ liệu (Cần độ chính xác tuyệt đối):
- Chiến lược: Tìm kiếm tham lam (Greedy) hoặc Sampling cực thấp
Temperature= 0.0 đến 0.2
Công thức cho Trợ lý viết lách, Sáng tạo content, Brainstorming ý tưởng:
- Chiến lược: Sampling kết hợp Top-p
Temperature= 0.7 đến 0.9Top-p= 0.9 (Chỉ lấy nhóm từ vựng hợp lý nhưng vẫn có sự đa dạng)Top-K= 40 (Cắt bỏ những từ rác)
VI. Kiến trúc Transformer
Kiến trúc Transformer là một cách thiết kế mô hình AI để xử lý chuỗi dữ liệu, đặc biệt là văn bản, bằng cách cho mô hình nhìn vào mối liên hệ giữa các từ trong cả câu thay vì chỉ đọc lần lượt từng từ một.
Mọi thứ bắt đầu vào năm 2017 với bài báo lừng danh "Attention Is All You Need" của Google. Ban đầu, nó chỉ được thiết kế chuyên biệt để dịch thuật.
Cơ chế Attention
Thay vì dịch từng từ một cách máy móc, cơ chế Attention cho phép mô hình nhìn vào các từ xung quanh để hiểu ngữ cảnh.
Transformer không cố hiểu từng từ theo kiểu tuần tự đơn giản, mà dùng cơ chế gọi là attention để quyết định từ nào nên được chú ý nhiều nhất khi xử lý một từ nào đó.
Ví dụ câu:
“Tôi bỏ cuốn sách lên bàn vì nó quá nặng.”
Khi hiểu từ nó, mô hình cần biết “nó” đang chỉ cuốn sách hay cái bàn.
Ví dụ khác:
Từ "bank" tiếng Anh có thể là "ngân hàng" hoặc "bờ sông". Nhờ chú ý vào các từ xung quanh như "money" (tiền) hay "water" (nước), Transformer sẽ xác định chính xác ý nghĩa của từ "bank" trong câu đó.
Góc nhìn sinh học: Hãy liên tưởng cơ chế Attention giống hệt cách con mắt con người hoạt động. Khi bạn đọc một cuốn sách, mắt bạn tập trung vào một chữ, nhưng tầm nhìn ngoại vi vẫn lờ mờ quét các chữ xung quanh để não bộ liên kết ý nghĩa một cách vô thức. Khái niệm AI này thực chất là sự mô phỏng sinh học tuyệt đẹp.
Rất nhanh sau đó, 3 nhánh phát triển lớn bùng nổ:
- Nhánh GPT (2018): Mô hình tự hồi quy (Auto-regressive), cực giỏi trong việc sáng tạo văn bản.
- Nhánh BERT (2018): Mô hình tự mã hóa (Auto-encoding), chuyên gia đọc hiểu và trích xuất thông tin.
- Nhánh BART/T5 (2019): Mô hình kết hợp (Sequence-to-sequence), bậc thầy dịch thuật và tóm tắt đa nhiệm.
Transformer học ngôn ngữ bằng cách nào?
Transformer học ngôn ngữ bằng cách tự học (Self-supervised learning): quét hàng tỷ trang web. Không cần con người ngồi dán nhãn từng câu, chúng tự tìm ra quy luật thống kê của ngôn ngữ.
Hai phương pháp học chính:
- Causal language modeling: Đoán từ tiếp theo trong câu (giống cách GPT đang làm).
- Masked language modeling: Bịt mắt một từ ở giữa câu và yêu cầu AI đoán từ đó là gì (giống cách BERT đang làm).
Pretraining (Huấn luyện trước) vs. Fine-tuning (Tinh chỉnh)
Pretraining là Bắt AI đọc toàn bộ internet từ con số 0. Quá trình này tốn hàng triệu đô la, đòi hỏi siêu máy tính và mất vài tháng.
Fine-tuning nghĩa là lấy một mô hình đã được Pretrain (như một sinh viên đã tốt nghiệp đại học), dạy thêm cho nó một chút kiến thức chuyên môn (như luật, y tế) bằng một bộ dữ liệu nhỏ. Quá trình này nhanh, rẻ và mang lại hiệu quả cực cao.
Pretraining đòi hỏi hàng ngàn GPU, hàng triệu đô la và dữ liệu bằng cả một mạng internet. Đó là việc của các ông lớn công nghệ. Việc của chúng ta là sử dụng lại các mô hình đã thông minh sẵn (Transfer learning), sau đó Fine-tuning (tinh chỉnh) chúng bằng một lượng dữ liệu nhỏ của riêng mình. Điều này giúp giảm thiểu chi phí tài nguyên, tiết kiệm thời gian, giảm lượng khí thải carbon mà vẫn đạt được độ chính xác tuyệt đối cho bài toán ngách.
Dưới góc độ thực tế doanh nghiệp hiện tại, Fine-tuning đôi khi vẫn hơi phức tạp. Một giải pháp thay thế đột phá mà bạn nên nghĩ tới là RAG (Retrieval-Augmented Generation) hoặc Prompt Engineering. Rất nhiều bài toán hiện nay có thể giải quyết dứt điểm chỉ bằng cách nhồi thêm tài liệu vào prompt cho mô hình đọc trước khi trả lời, mà hoàn toàn không cần đụng đến Fine-tuning.
Cấu trúc Encoder và Decoder
Encoder (Bộ mã hóa): Nhận đầu vào, đọc cả câu cùng lúc theo hai chiều (trái sang phải, phải sang trái) để hiểu sâu sắc ngữ cảnh. Rất phù hợp cho các bài toán phân loại.
Decoder (Bộ giải mã): Tạo ra đầu ra, viết từng từ một và chỉ được phép nhìn vào những từ đã viết trước đó (một chiều). Rất phù hợp cho các bài toán sáng tạo văn bản.
Lưu ý: Các mô hình có thể dùng riêng Encoder (BERT), riêng Decoder (GPT), hoặc ghép cả hai lại với nhau (T5, BART).
Tại sao thế giới LLM hiện nay (GPT, Claude) lại chuộng Decoder-only hơn là ghép cả hai?
Bài học phân loại rất rõ ràng, nhưng trong thực tế ngành AI hiện tại có một sự chuyển dịch lớn. Cấu trúc Encoder-Decoder vốn dĩ ưu việt hơn về mặt lý thuyết vì nó tận dụng được cả 2 thế mạnh. Tuy nhiên, các kỹ sư nhận ra rằng: Khi bơm một lượng dữ liệu và tham số đủ khổng lồ vào kiến trúc Decoder-only, nó phát sinh ra cái gọi là "trí thông minh tự phát" (Emergent abilities). Một mô hình GPT (chỉ Decoder) giờ đây hoàn toàn có thể dịch thuật và tóm tắt xuất sắc không kém gì mô hình Seq2Seq, đồng thời lại dễ huấn luyện và mở rộng hơn trên các cụm siêu máy tính.
VII. Góc nhìn thực tế
Đừng coi AI là một Nhà thông thái thấu hiểu mọi chân lý. Hãy coi AI là Một diễn viên xuất sắc đã đọc mọi kịch bản trên đời. Nó diễn lại những gì nó đọc được. Trách nhiệm của chúng ta không phải là tin tưởng nó tuyệt đối, mà là sử dụng nó có màng lọc.
Khi sử dụng LLM, bạn cần ngồi đọc hàng ngàn câu trả lời của AI, sau đó "phạt" điểm nếu AI nói bậy và "thưởng" điểm nếu AI trả lời chừng mực. AI sẽ dần tự điều chỉnh hành vi để lấy điểm thưởng. Đây là cách tôi ví von, trong thực tế bạn cần prompt để đưa AI vào khuôn khổ.
Guardrails (Hệ thống rào chắn): Trong ứng dụng thực tế, không ai để LLM trả lời trực tiếp cho người dùng cuối. Bạn phải xây dựng cơ chếchuyên để nhận diện nội dung độc hại hoặc thông tin đưa vào không có trong domai knnowledge mà sản phẩm bạn cung cấp cho ennd user.
Ví dụ: nếu LLM tạo ra câu trả lời có điểm Toxic > 80%, hệ thống sẽ tự động chặn lại và trả về câu: "Tôi xin lỗi, tôi không thể trả lời câu hỏi này".
Và cuối cùng đừng quên rằng: "AI có thể tạo ra thông tin không chính xác hoặc mang tính định kiến. Vui lòng tự xác minh thông tin." (Đây là tiêu chuẩn bắt buộc của các tập đoàn công nghệ lớn hiện nay).

![[Long-form] Hiểu Generative AI một cách đơn giản](/content/images/size/w720/2024/04/generative-AI-la-gi.png)

Comments ()